

序言
YOLO(You Only Look Once)是基于深度神经网络的目标检测算法,用在图像或视频中实时识别和定位多个对象。YOLO的主要特点是速度快且准确度较高,能够在实时场景下实现快速目标检测。被广泛应用于计算机视觉领域,包括实时视频分析、自动驾驶、安防监控、智能交通、缺陷检测等。
目前yolo目标识别算法已经发展到yoloV9版本,但是yoloV5经过高度优化,非常适用于实时应用,并且其FPS(每秒帧数)非常出色,使其成为实时应用的首选。
yolo目标识别算法一般用于工作室本地识别比较复杂的图像或者个人玩家本地高定脚本,不太适合互联网环境。原因是部署yoloV5的GPU服务器一般是在本地,也就是局域网内,其他用户想要访问到本地GPU服务器,则需要一台公网的服务器进行中转(做端口印射或者内网穿透)。受限于公网服务器的转发性能和带宽,识别速度和同时识别的数量会很低,不适合大规模商用(有钱去运营商拉专线/IDC托管的当我没说)。既然是工作室使用或者高定脚本,那么对于显卡的要求自然会很高,所以在学习期间,如果显卡性能不足建议更新显卡后再来学。否则花了大力气训练出来,识别速度慢就得不偿失了。如果打算应用于对实时性要求高的游戏中(如竞技类游戏,建议显卡不低于3070)
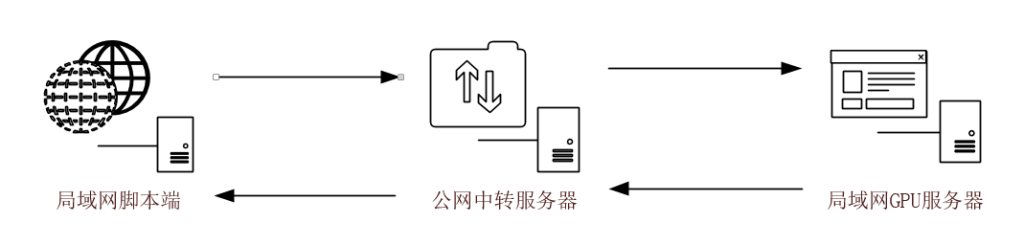
建议使用2060及其以上级别的显卡,10系列((如1060、1070、1080等))或者16系列(1660、1660s等)只能支持CUDA10.X版本,但是在安装CUDA10.X时会遇到很多问题。本文以win10专业版、2060显卡、CUDA11.8版本进行演示。如何安装CUDA10.x版本请自行百度。
本文内提供软件只支持win10,本文内提供软件只支持win10,本文内提供软件只支持win10,并且要保证系统是正规渠道下载的win10镜像(阉割版系统可能会报错),重要的事情说三遍。部分软件以上传至百度网盘,点此下载,提取码uq86
一、准备工作
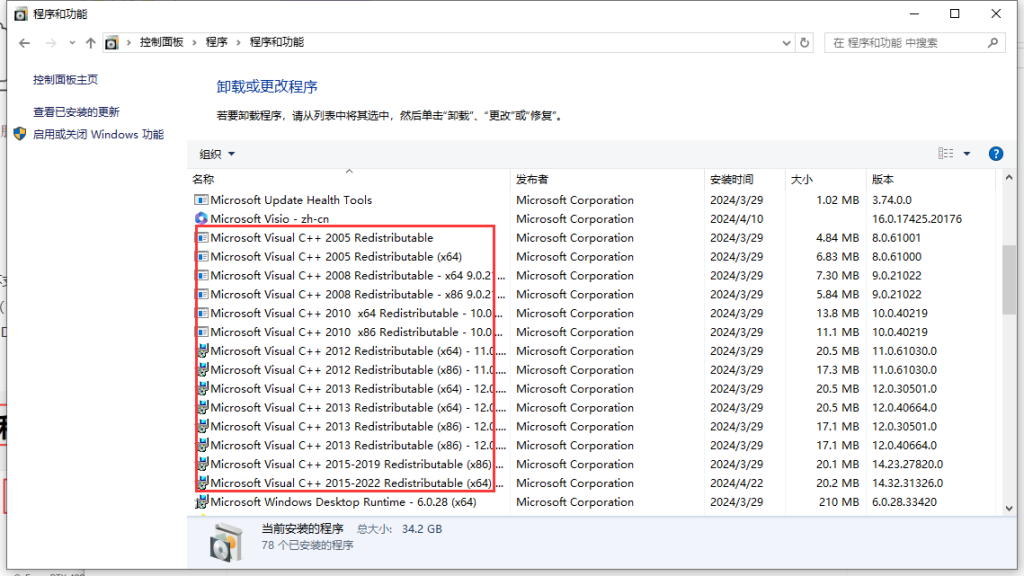
1.安装Visual C++。如果提示设置失败,就打开一下控制面板,看下之前是否安装过,如果安装过了就不必再安装。
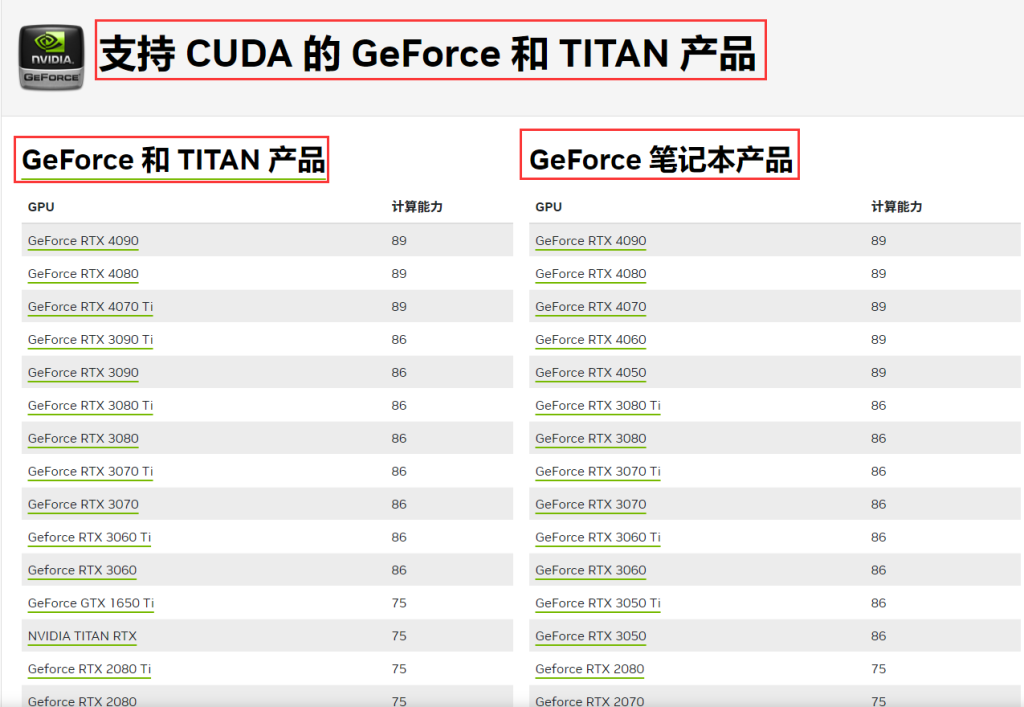
2.查看显卡是否支持CUDA,不支持就别折腾了,点此跳转
3.更新N卡驱动,英伟达驱动下载,选择studio版本

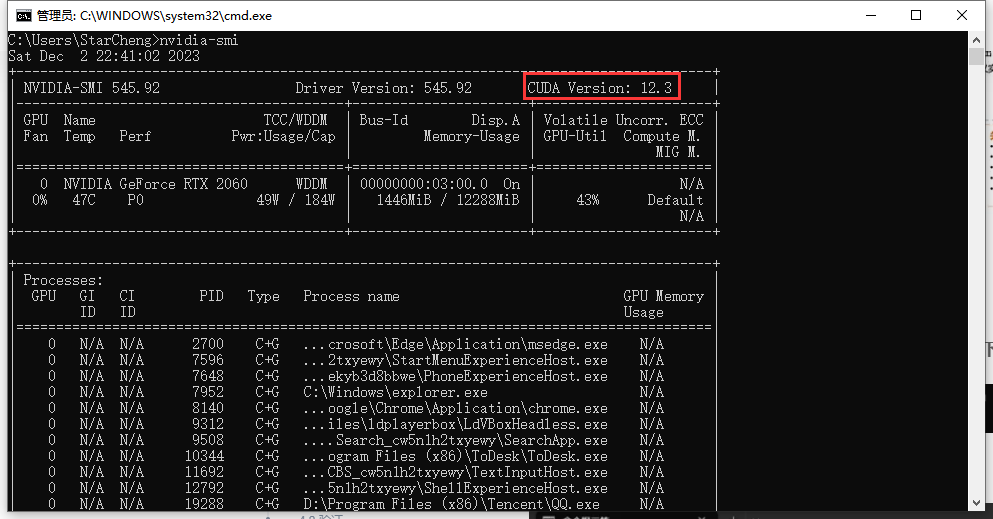
4.命令提示符输入nvidia-smi,查看显卡支持的最高CUDA版本。
TIPS:目前pytorch有CUDA11.8和CUDA12.1版本(截止2024.4.24),40系以下的显卡建议安装CUDA11.8版本(装12.1也行),因为CUDA11.8支持百度飞浆的文字识别paddleOCR(本地部署PaddelOCR使用GPU加速方法点此跳转,yoloV5+文字识别基本上所有的游戏脚本都可以做了,paddleOCR目前不支持CUDA12.1)。40系以上的显卡为了避免出现兼容性问题,建议使用CUDA12.1。
5.根据选择的版本安装CUDA
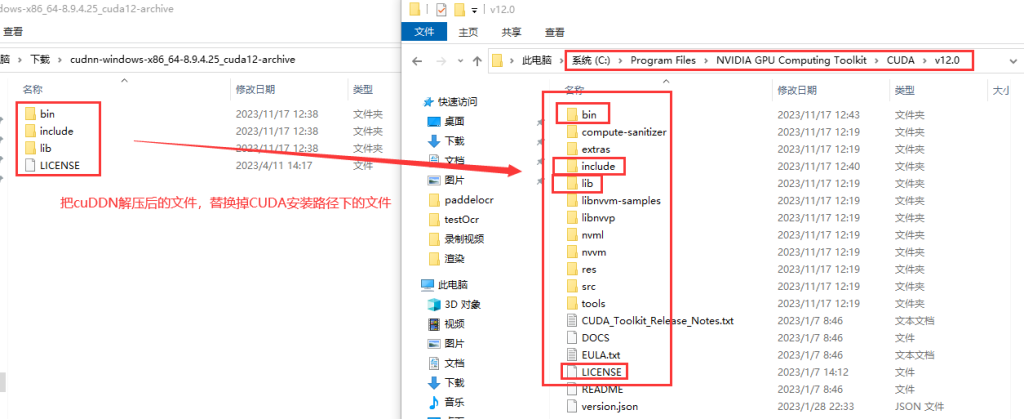
6.根据CUDA版本,下载对应的cuDDN, 将cuDDN解压后,替换CUDA安装路径中的文件

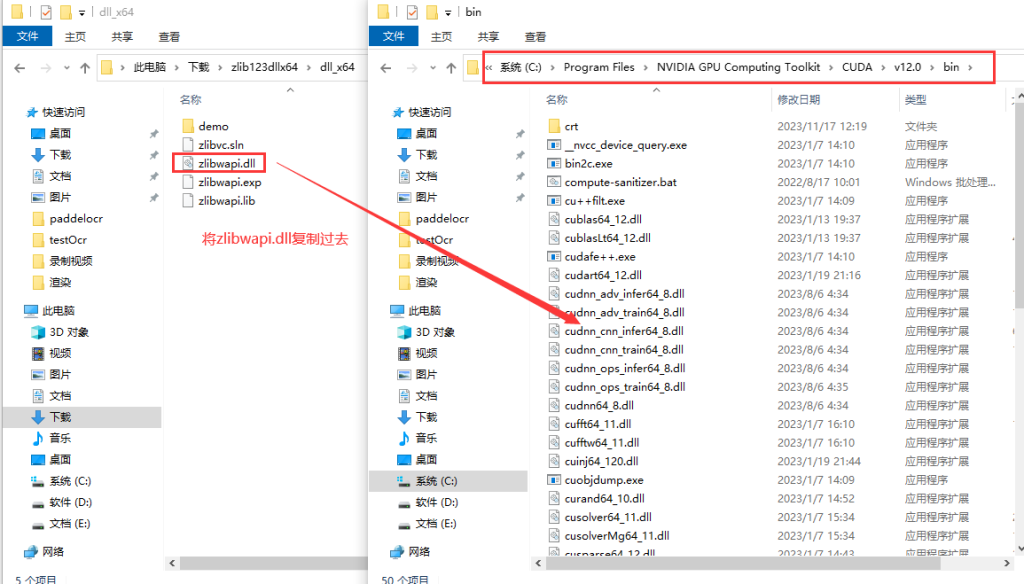
7.下载zlib123dllx64,解压后将zlibwapi.dll复制CUDA安装路径的bin目录下
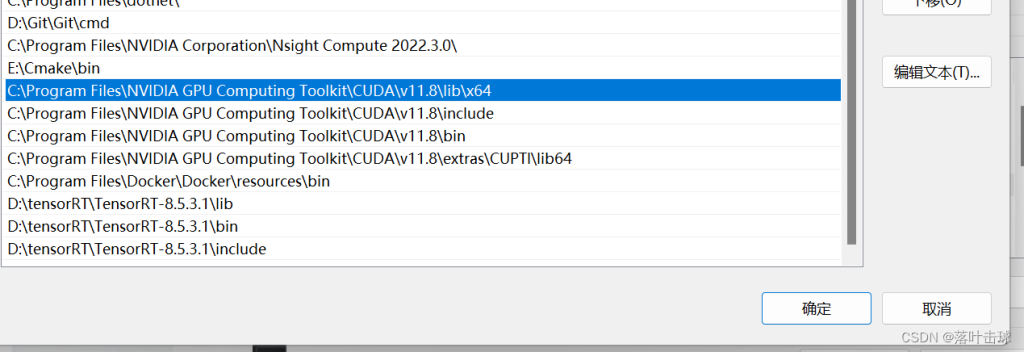
8.此电脑-属性-系统高级设置,添加CUDA路径到系统环境变量
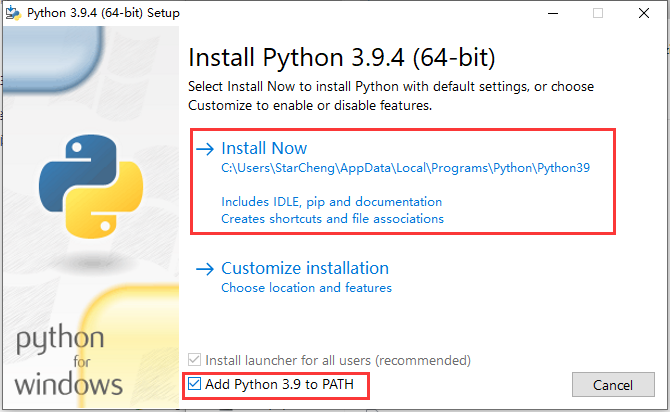
9.安装python3.9.4
10.命令提示符升级pip
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip11.命令提示符配置清华镜像源
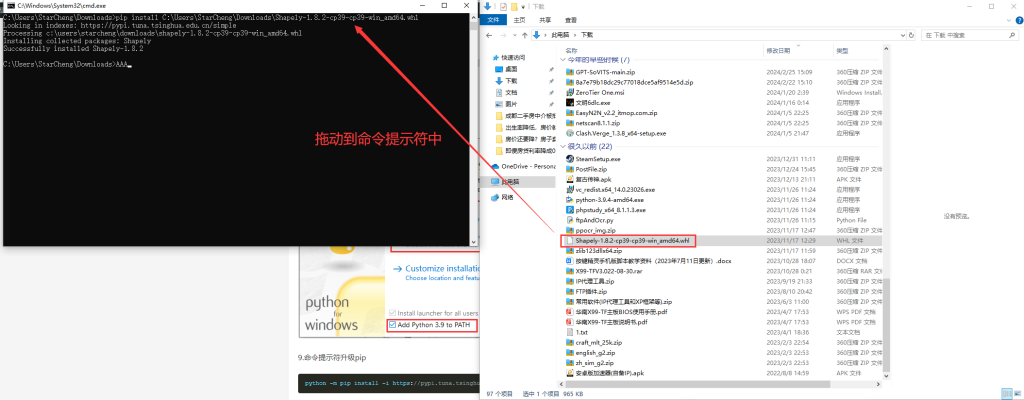
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple12.命令提示符安装Shapely-1.8.2-cp39-cp39-win_amd64,输入 pip install ,注意install后面有一个空格。再将Shapely-1.8.2-cp39-cp39-win_amd64.whl文件拖到到命令提示符中,按回车安装
13.根据CUDA版本,命令提示符安装pytorch
#CUDA 11.8安装这个
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118#CUDA 12.1安装这个
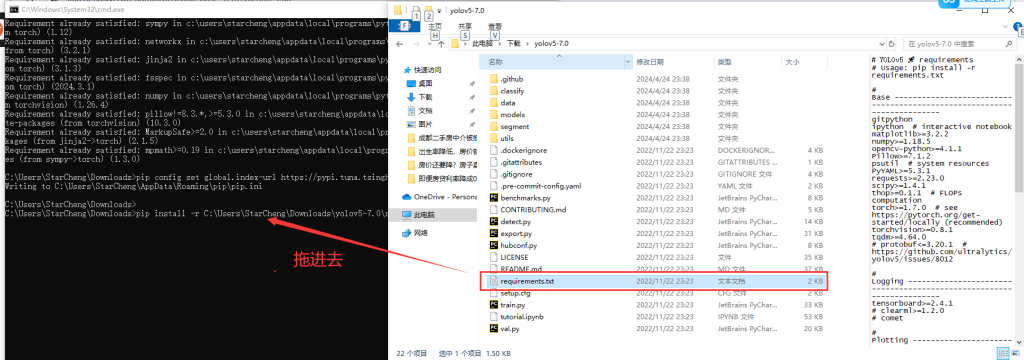
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu12114.安装yoloV5依赖,解压yolov5-7.0.zip,命令提示符输入pip install -r ,注意-r后面有一个空格,将requirements.txt拖入命令提示行窗口,按回车进行安装。
二、检查环境
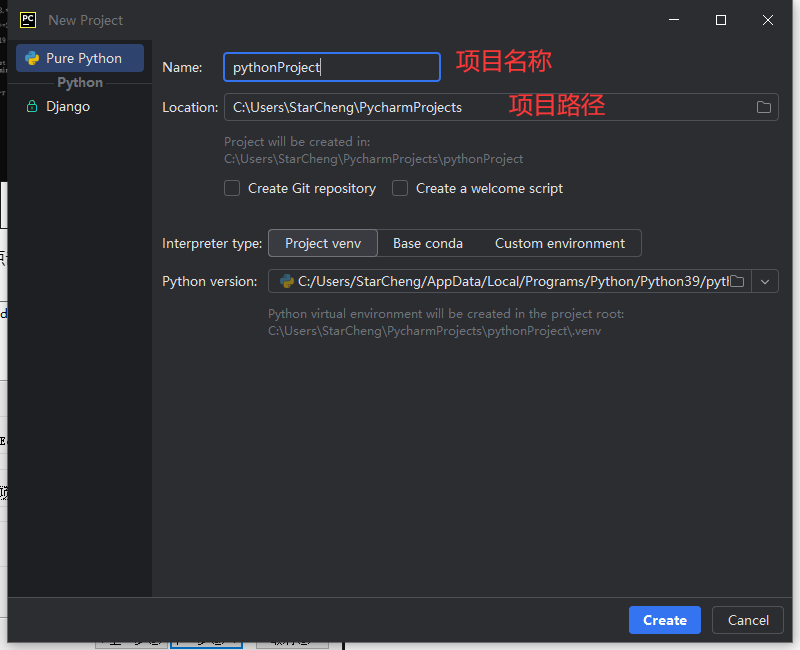
1.安装pycharm,点击new Project,新建一个项目,项目名称自定义,项目路径自定义(路径不要有中文名称就行),点击create完成创建,再将刚刚解压好的yolov5-7.0文件夹放在项目路径中。
2.将yolov5s.pt复制到yolov5-7.0根目录中
3.设置系统解释器
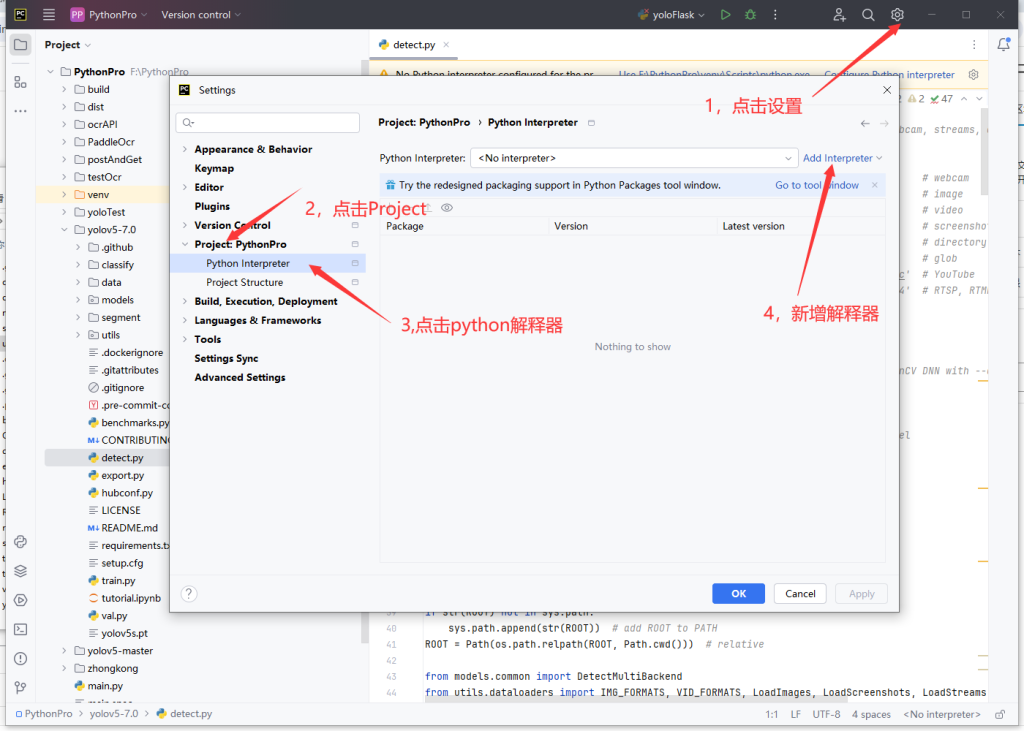
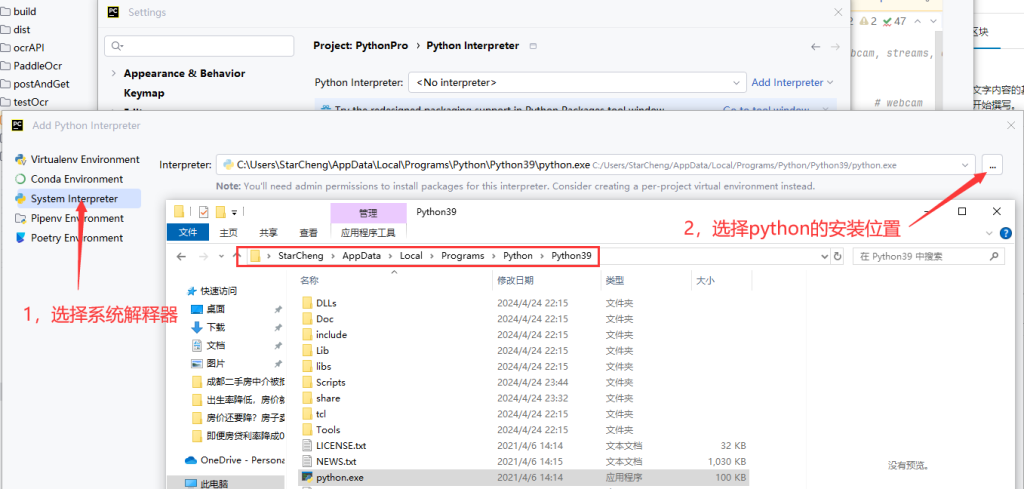
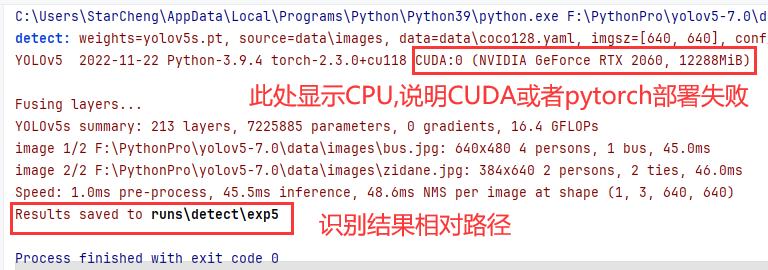
4.运行decete.py,双击decete.py,右键选择run 'decete.py',如果报错,大概率是pip install安装的依赖有缺失,重新安装一遍即可。如果不报错,但是显示的是CPU,说明CUDA或者pytorch部署失败,需要卸载掉重新部署一遍。
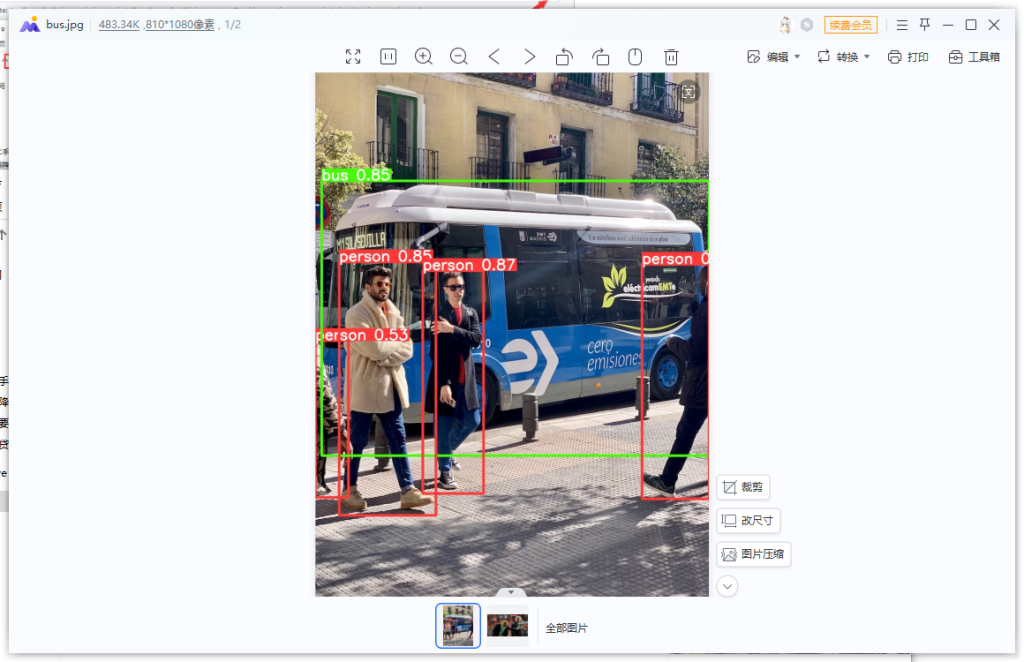
5.查看识别结果,打开yolo5-7.0目录下的run\detect\exp目录,如果图片进行了标记,则说明yoloV5部署完成。
三、重要参数说明
1.打开detect.py,找到def parse_opt()
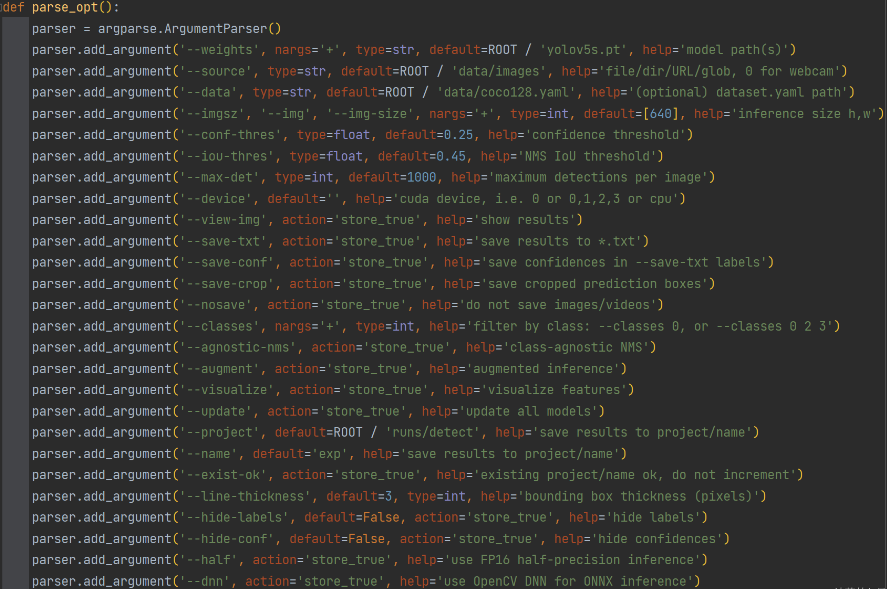
2.weights:网络权重,默认是yolov5s.pt。建议不动这个参数

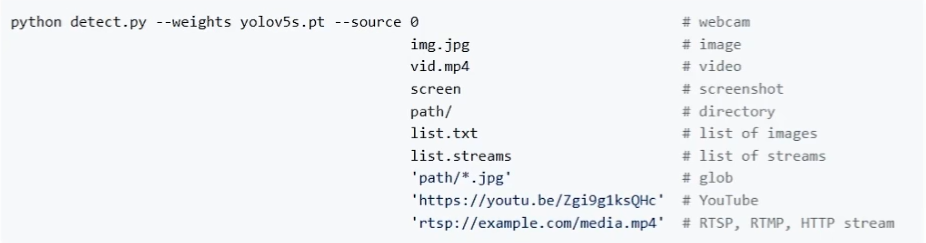
3.source:网络输入路径,默认是文件夹,也可以指定文件类型或者摄像头,网络推流等,根据实际情况调整

4.data:配置文件路径,默认coco2018数据集。数据集的作用是:训练、验证效果、泛化测试。将训练好的模型配置文件路径放进去

5.imagesz,img,img-sz:检测图片前,会把图片调整为640*640的尺寸。推理的尺寸最好和实际尺寸一致,检测效果最好。建议不动这个参数

6.conf-thres:置信度,类似于按键精灵中的找图找色的相似度,阈值越低框越多

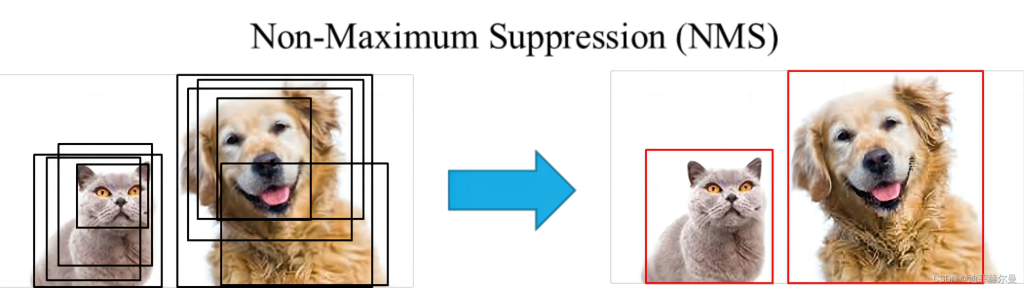
7.iou-thres:交并比阈值,防止同一个目标被识别为多个,阈值越低框越少

8.max-det:最大检测数量,根据实际情况调整

9.device:默认使用GPU推理,有多张显卡,从0开始填写 0,1,2,3,4……根据实际情况调整,只有一张显卡就不动这个参数

10.view-img:实时显示检测结果

python detect.py --view-img11.save-txt:把检测结果保存为txt

python detect.py --save-txt12.save-conf:把置信度保存为txt

python detect.py --save-txt --save-conf13.save-crop:把检测到的目标剪裁成图片进行保存

14.剩下的参数有兴趣自行了解,保存默认即可,不影响我们使用。
四、数据集构建
1.命令提示符安装标注工具
#安装labelimg
pip install labelimg2.命令提示符启动标注工具
#启动labelimg
labelimg3.标注工具预设
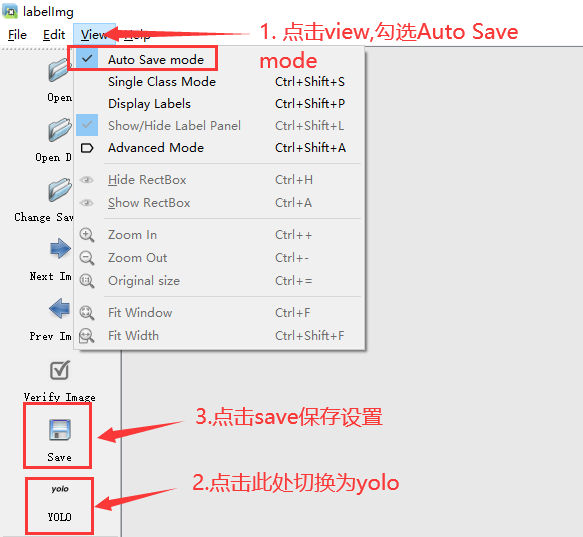
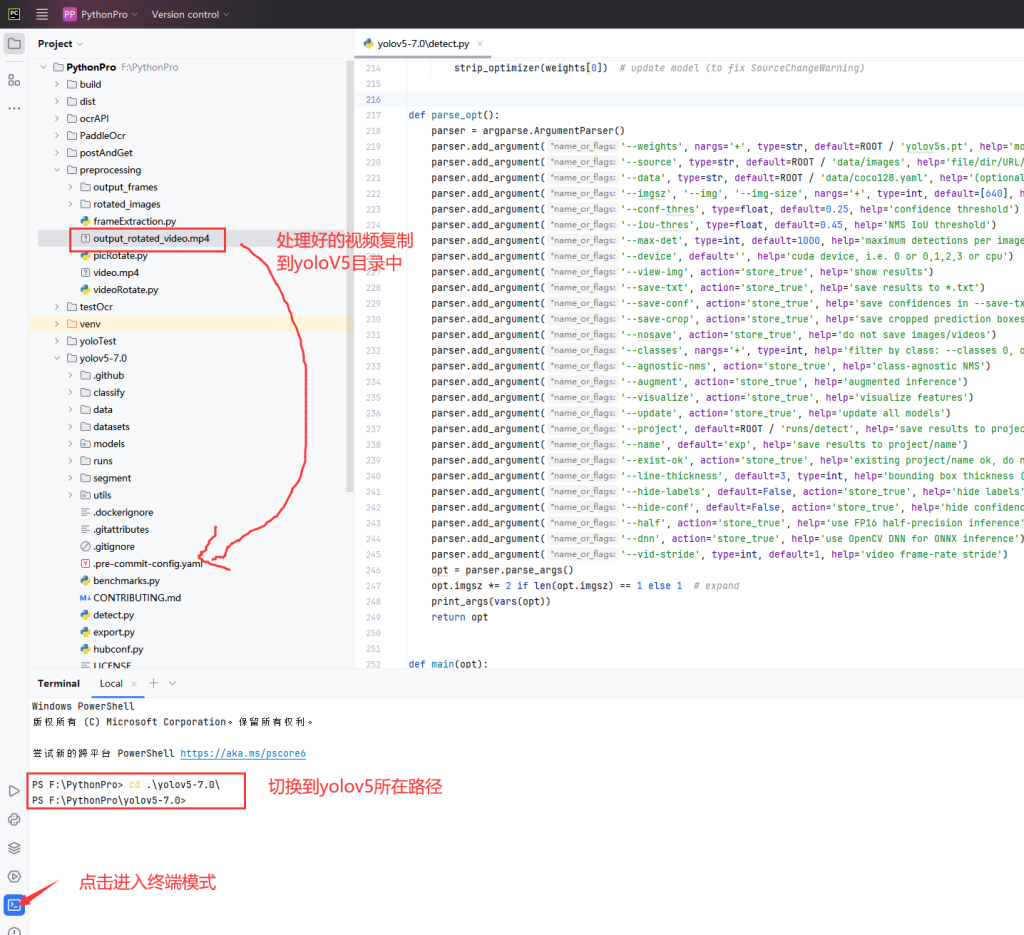
4.视频和图片预处理,根据实际情况使用frameExtraction.py进行视频抽帧,使用picRotate.py对图片进行旋转,使用videpRotate.py对视频进行旋转。预处理源码点此下载
5.创建datasets目录,并在该目录中,分别创建images目录和labels目录,将预处理完毕的图片,复制到images目录中
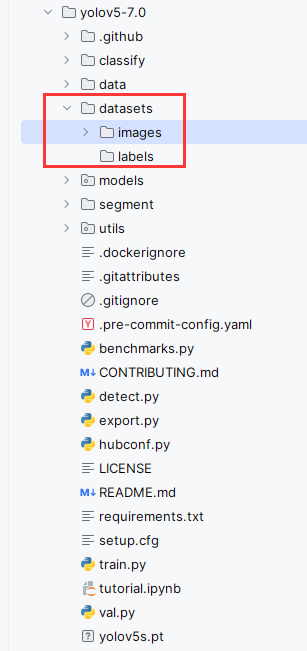
6.开始标注
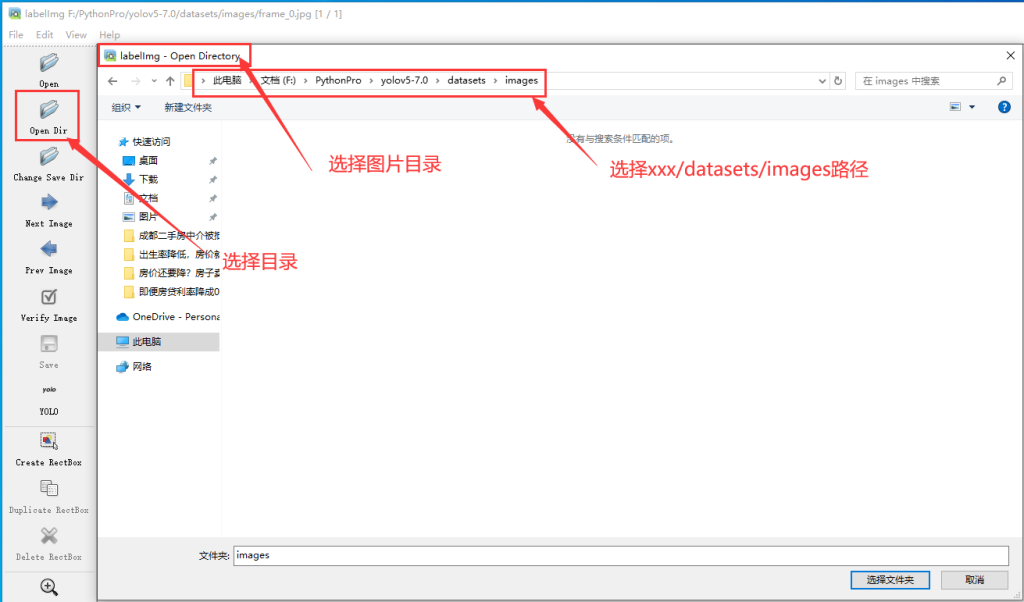
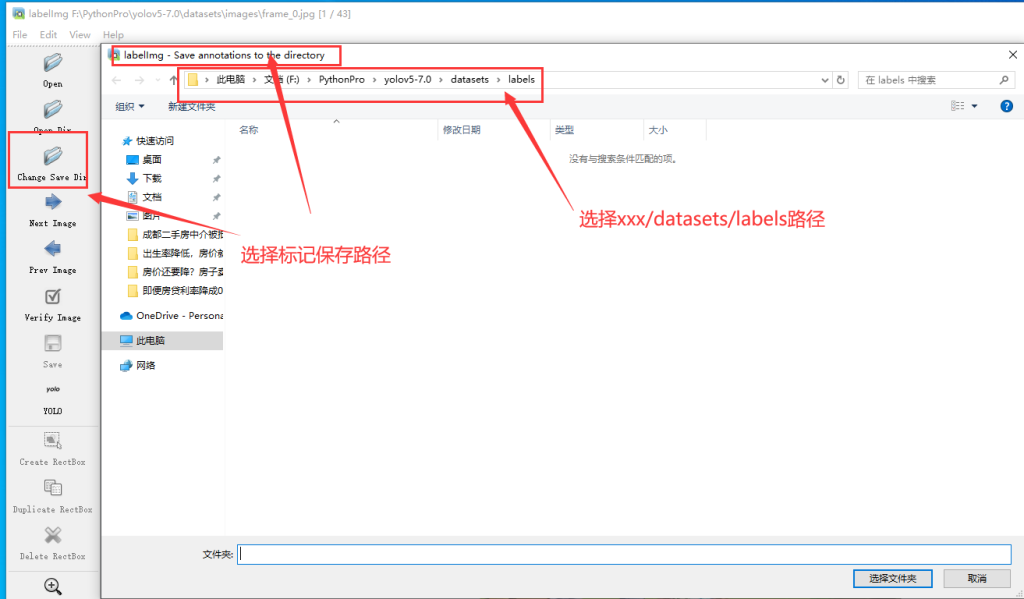
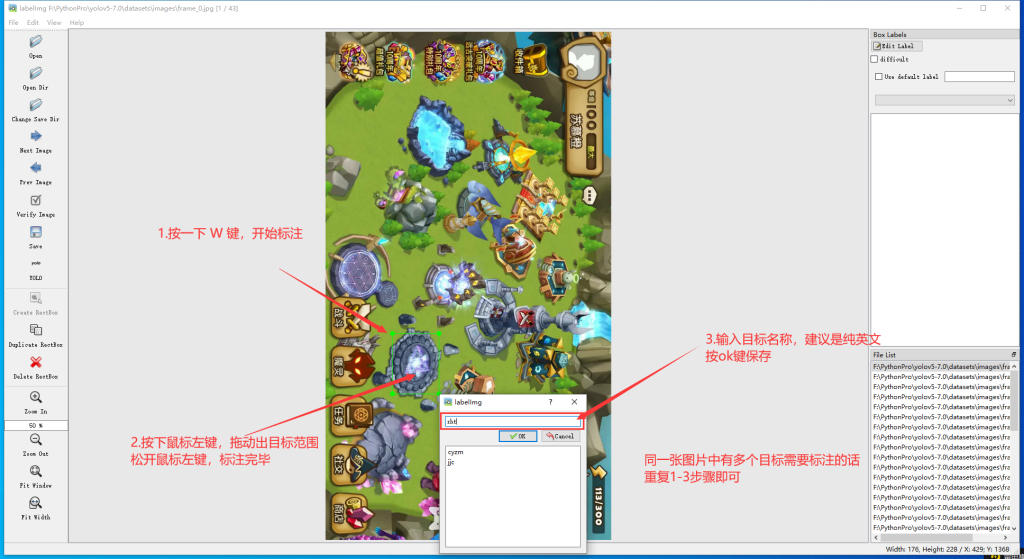
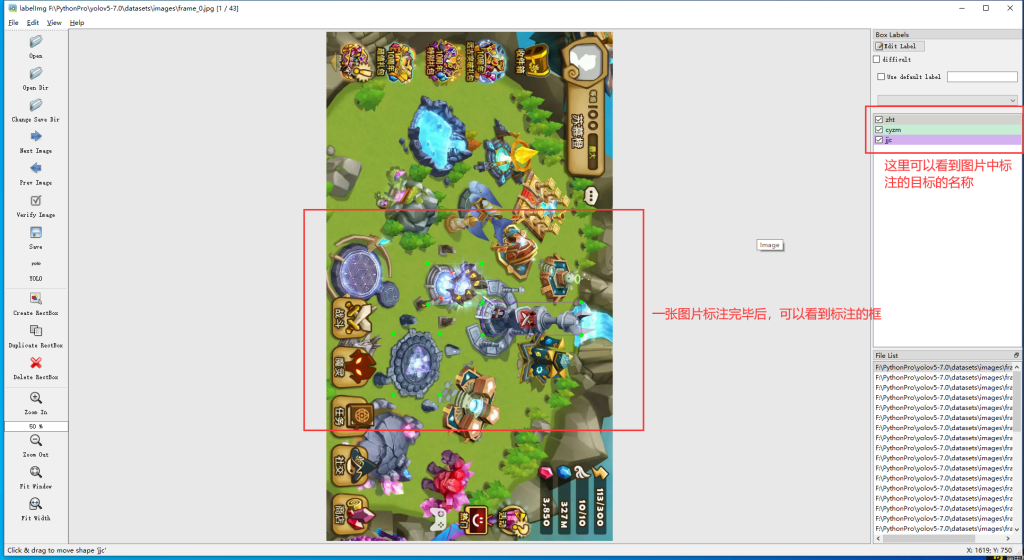
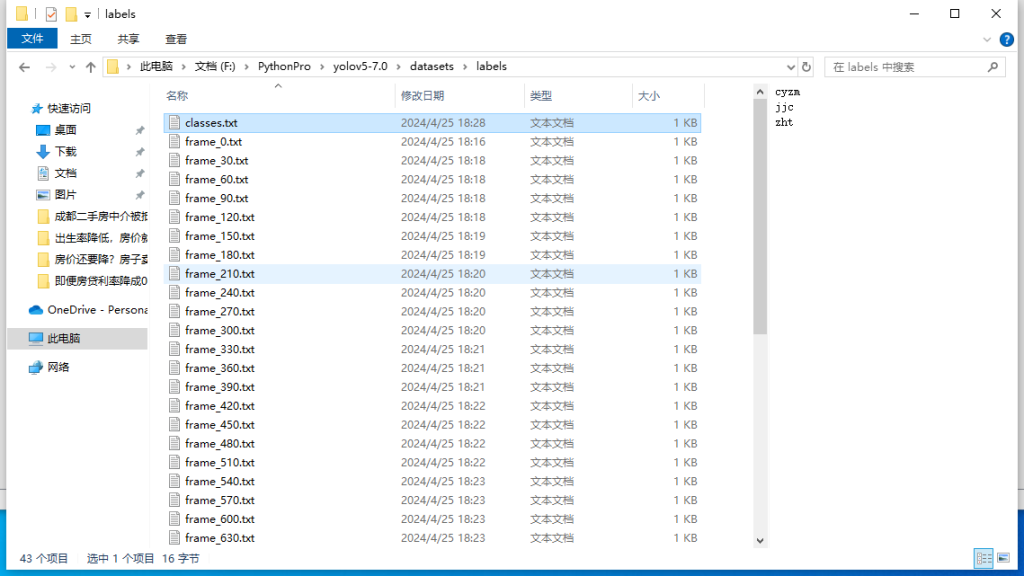
7.按 a 向前选择,按 d 向后选择。将所有图片标注完即可,标注完毕后,在labels里面可以看到每张图片的标签信息,建议每个label标注100次。
五、训练模型
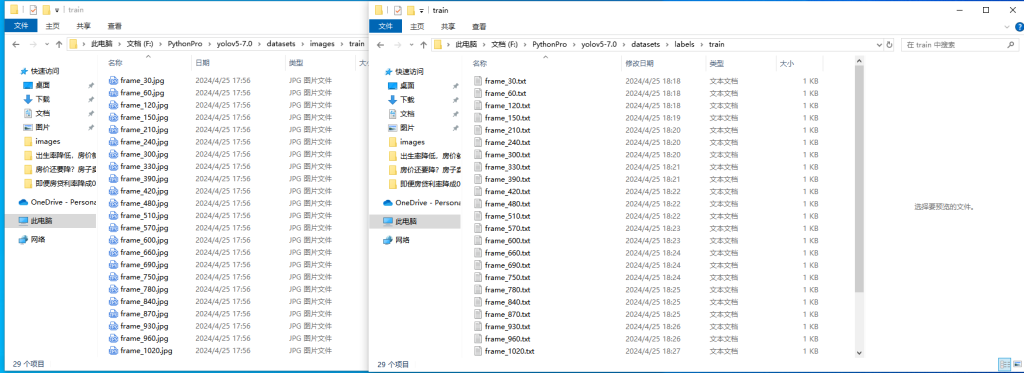
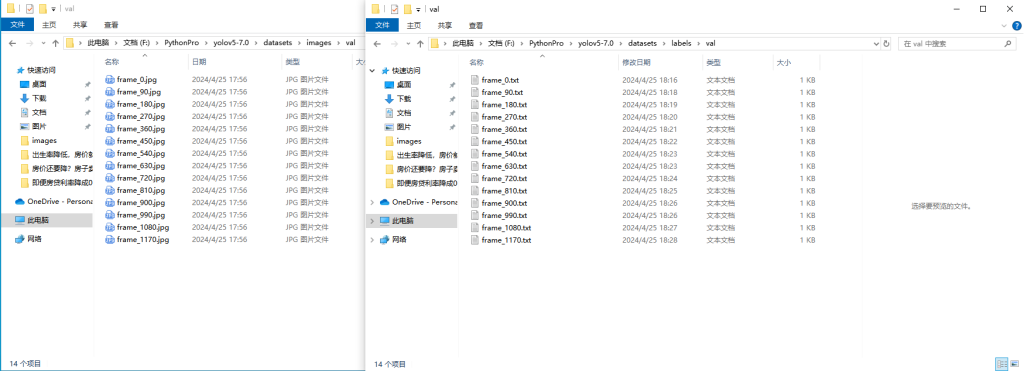
1.数据整理:images和lables路径下,都新建train目录和val目录,然后把标注好的图片和标签,一部分放进train,一部分放进val。train和val的比例建议为3:1

注意:images/train里面和图片和labels/train标签要对应,images/val里面和图片和labels/val标签要对应起来
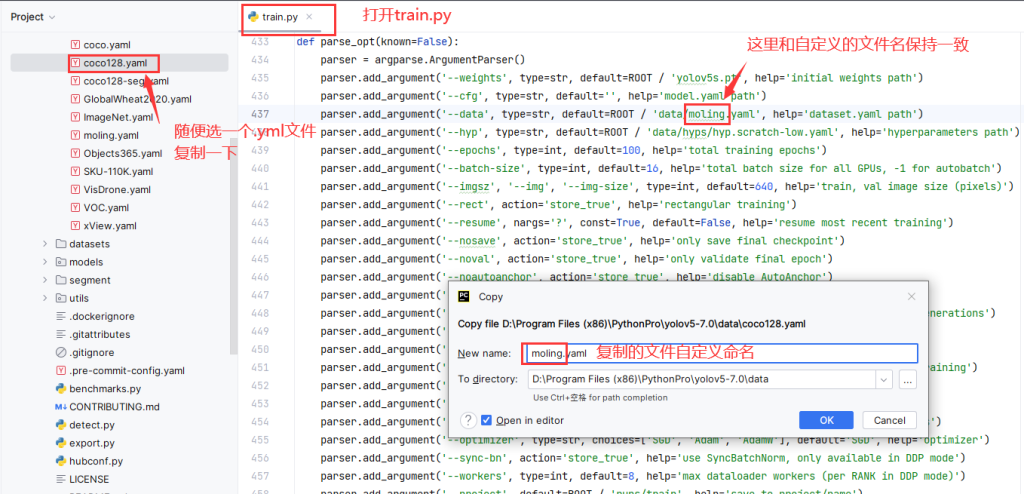
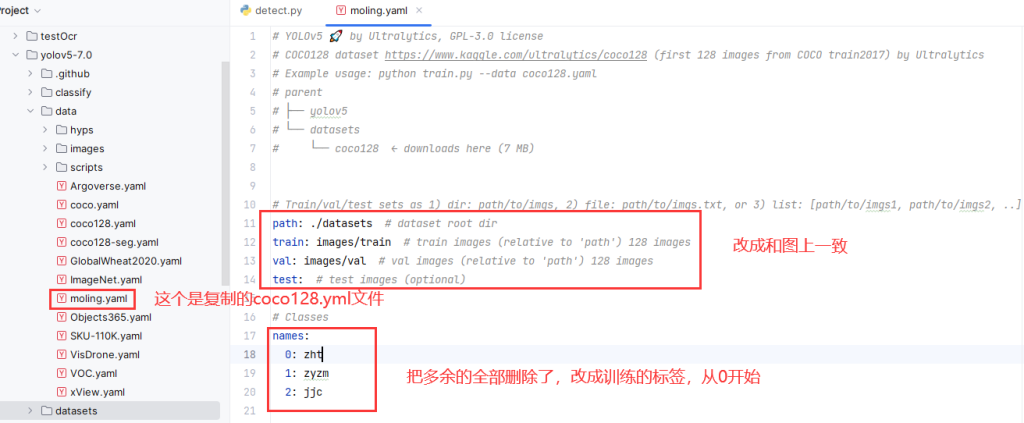
2.更改模型
3.运行train.py:如果出现下图中的报错,就把这行代码添加至cmd.py的第64行处并保存
os.environ['GIT_PYTHON_REFRESH'] = 'quiet'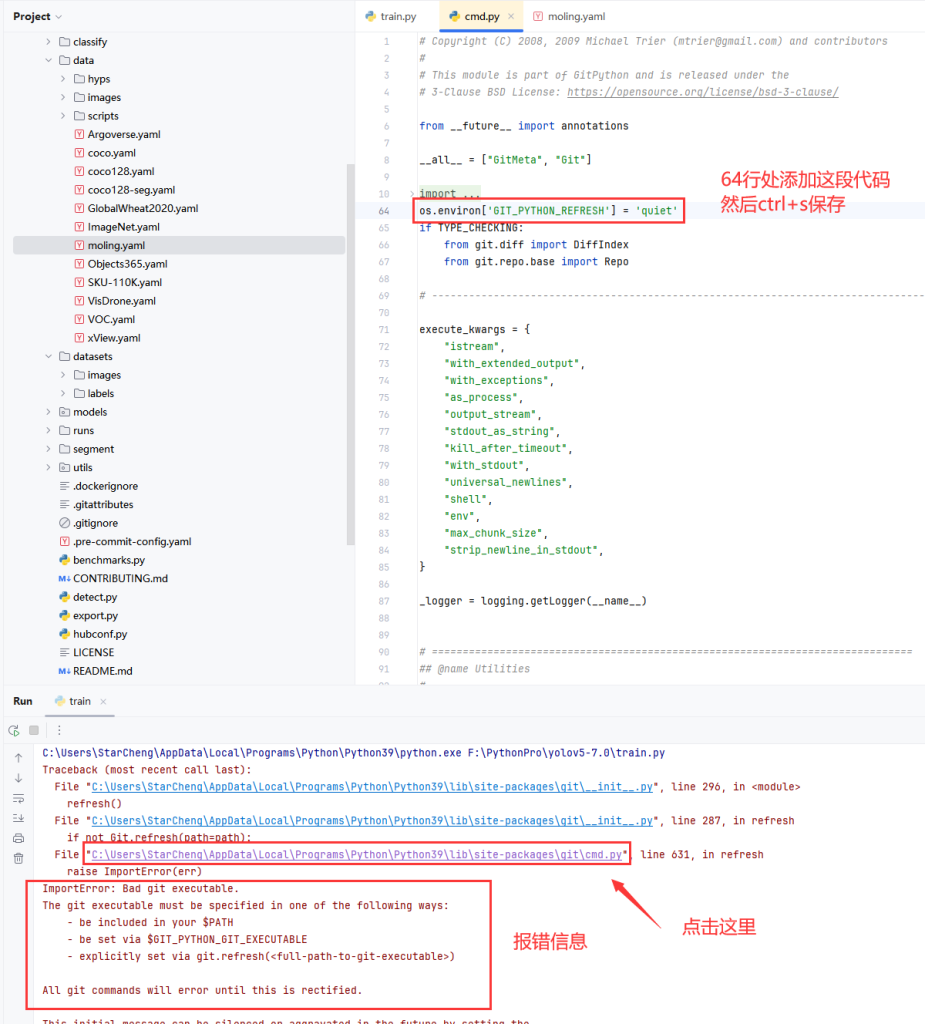
4.出现如下信息则说明代码证运行,第一次运行会下载字库文件,默认训练100轮,建议设置训练轮数为300,耐心等待训练完毕

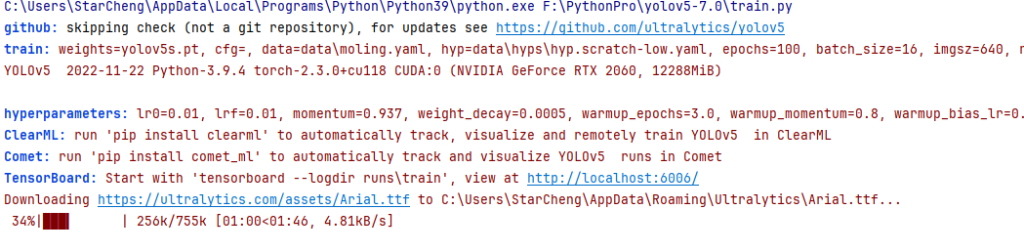
5.训练完毕,mAP50的值通常在0.5-0.95之间,建议训练到0.8以上。
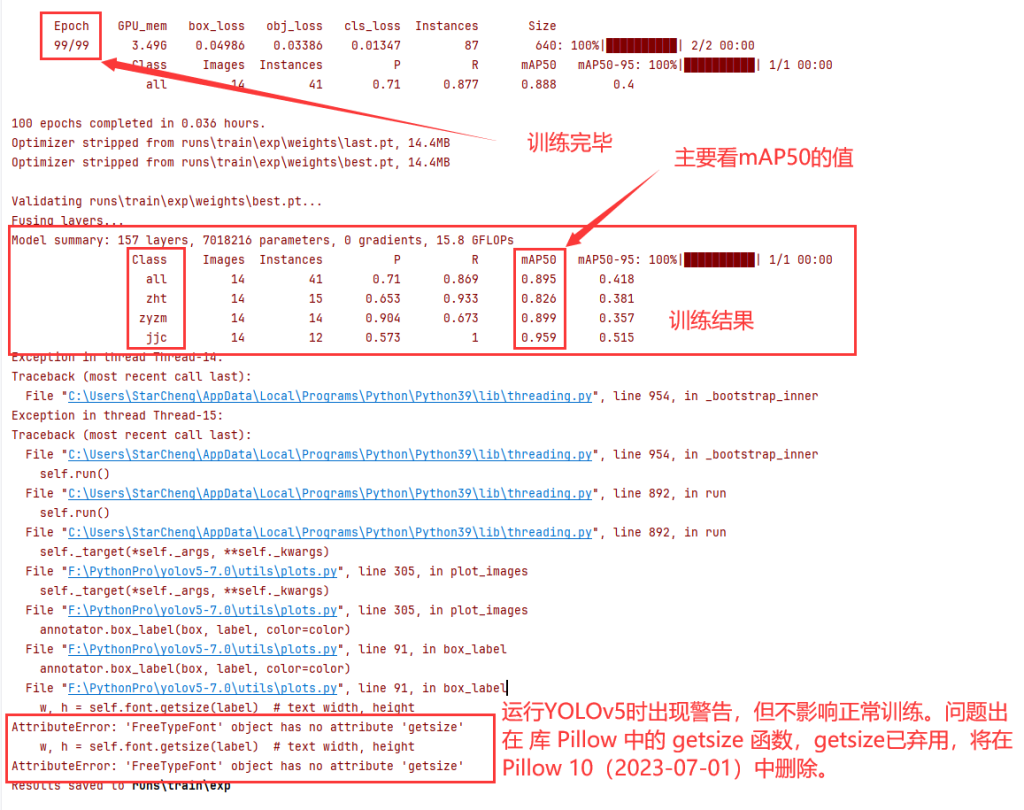
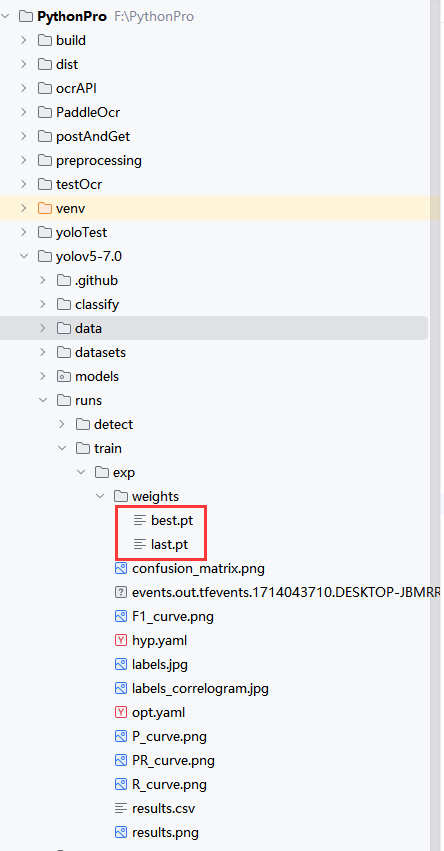
6.查看训练结果,训练好的模型保存在runs/train/exp/weight中,best.pt是效果最好的模型,last.pt是最后一次训练的模型。加载模型时使用best.pt,接着上一次训练用last.pt
六、验证模型
1.进入终端模式,输入代码
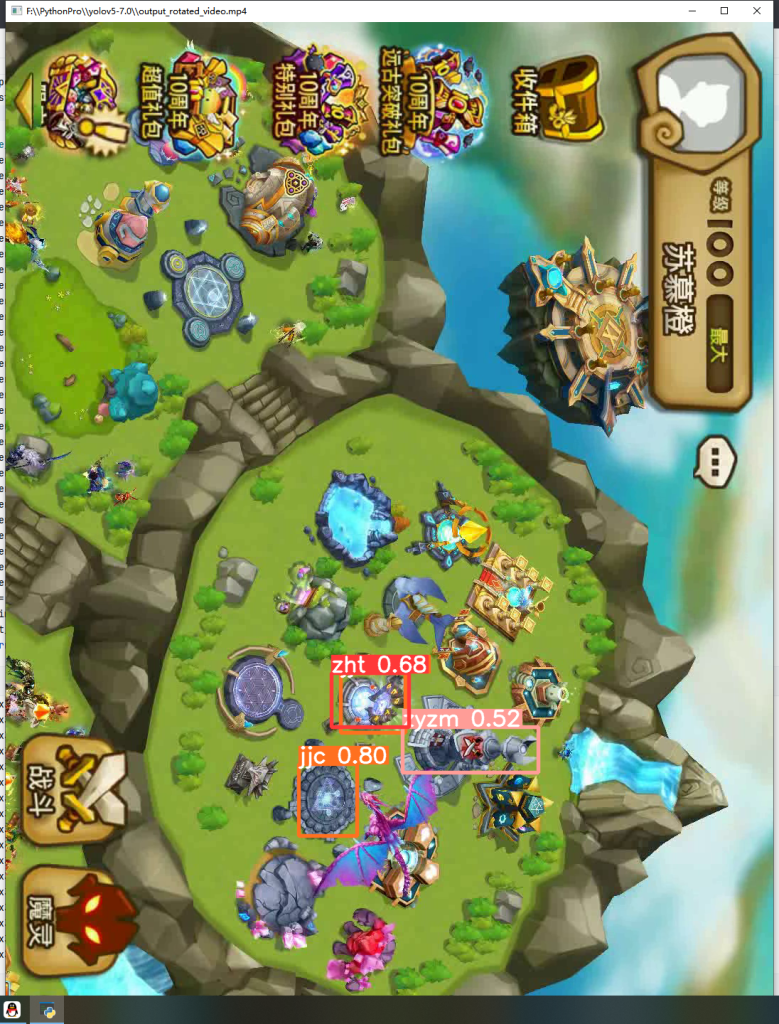
python .\detect.py --weights runs/train/exp/weights/best.pt --source output_rotated_video.mp4 --view-img

2.显示视频分析结果,出现方框标记,说明模型训练成功。
七、调用模型
1.安装框架和依赖
#安装flask
pip install flask
#安装gevent
pip install gevent2.在yoloFlask.py中,点此下载yoloFlask.py,修改为yoloV5绝对路径和模型绝对路径,再运行yoloFlask.py

3.按键精灵调用yoloV5,由于识别需要对图片进行上传,所以需要引用我的上传/下载插件
Import "fileUPAndDown.mql"
dim pictureName="test"
Dim path=GetSdcardDir()&"/"&pictureName&".png"
SnapShotEx path,0,0,0,0,0
Dim serverIP="192.168.0.9:9090"
Dim UpLoadPath="./"
dim filePath="/sdcard/test.png"
fileUPAndDown.postFileUpLoad serverIP, UpLoadPath, filePath
dim t=TickCount()
Dim link="192.168.0.9:9090/detect?picName="&pictureName
TracePrint link
Dim back = Url.HttpPost({"url":link})
TracePrint back
TracePrint TickCount()-t
dim tb=Encode.JsonToTable(back)
dim arr=tb["msg"]
TracePrint UBound(arr)
For i = 0 To UBOUND(arr)
dim newarr=arr(i)
dim 坐标=newarr["coordinates"]
dim 置信度=newarr["confidence"]
dim 类型=newarr["class"]
If 置信度 >= 0.8 Then
TracePrint (坐标(0)+坐标(2))/2,(坐标(1)+坐标(3))/2
End If
Next4.返回识别结果

八、端口映射(补充内容)
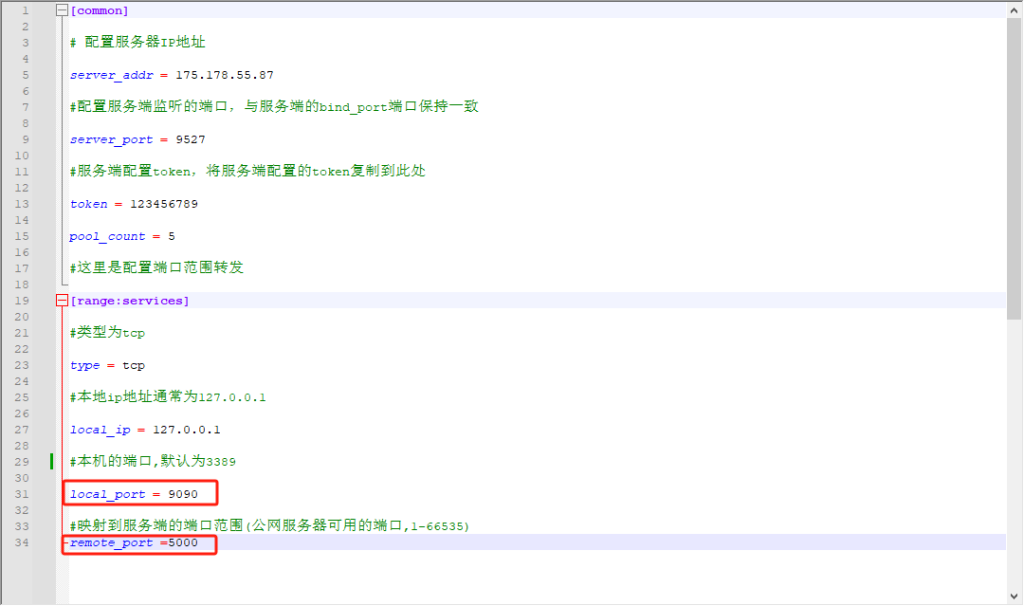
1.如果你有外网客户端访问内网部署的GPU服务器的需求,可以使用frp进行内网穿透,frp部署方式点此跳转。
2.服务端按照文档进行配置,客户端按下图进行配置,local_port必须填9090,remote_port随便填一个就行。
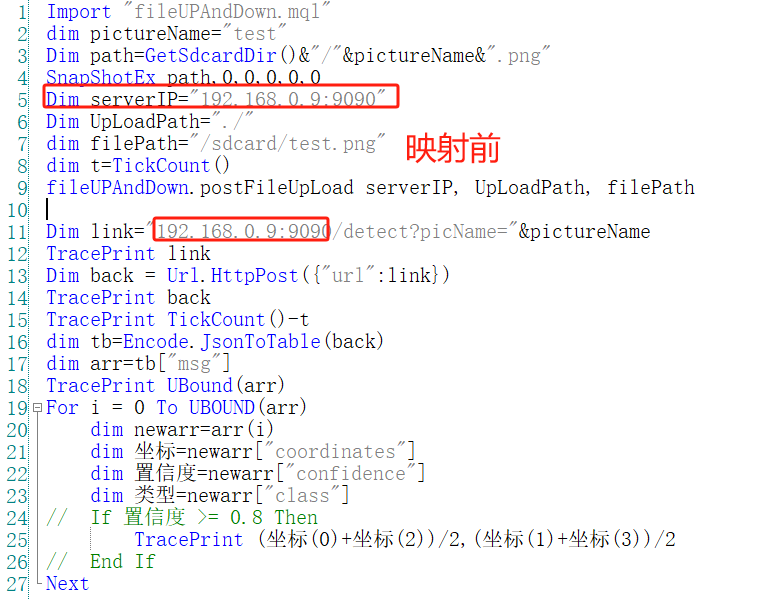
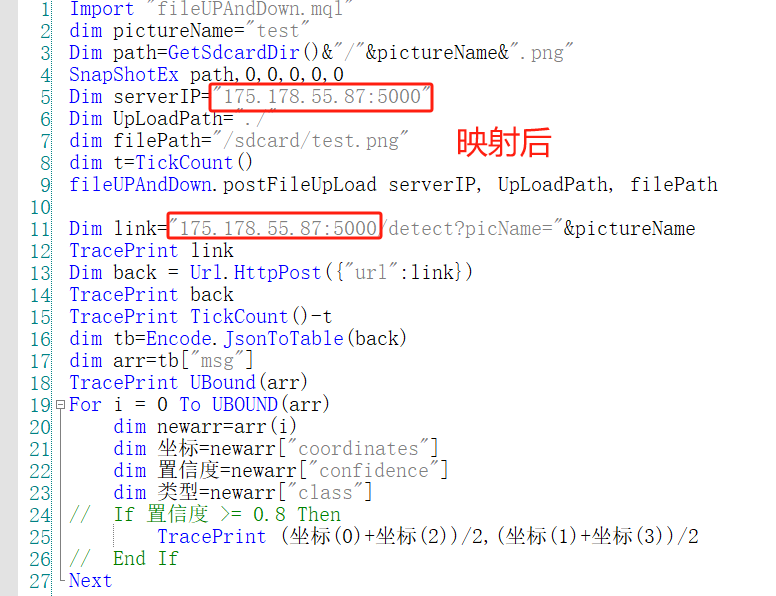
3.映射后需要将调用地址更改为映射的地址。比如本地部署调用地址是192.168.0.9:9090/XXX,使用frp把9090端口映射到了175.178.55.87:5000端口。那么就需要在客户端修改调用地址为175.178.55.87:5000。
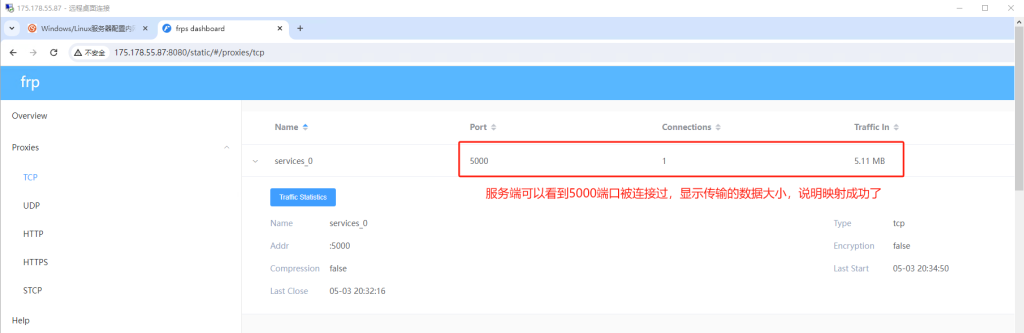
4.客户端调用返回结果,速度慢的主要原因就是传输得比较慢,所以延迟大。

九、负载均衡(补充内容)
1.YOLOv5进行图像识别,是一个典型的高并发、计算密集型应用场景。在yoloFlask.py中使用了gevent框架应对高并发的情况,同时还可以使用Nginx作为负载均衡器,来分发请求到多个Flask实例。
2.点此下载Nginx,选择Stable version版本,解压后替换Nginx.conf配置,点此下载Nginx.conf
3.以管理员模式运行Nginx.exe,窗口会闪一下,在任务管理器中可以看到两个Nginx.exe进程。一定要先启动Nginx,再启动Flask实例。
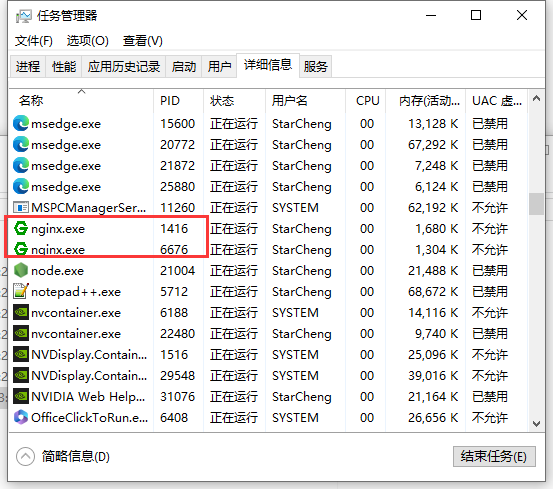
4.通过命令行启动多个实例,每个实例监听不同的端口。
python yoloFlask.py 9090
python yoloFlask.py 9091
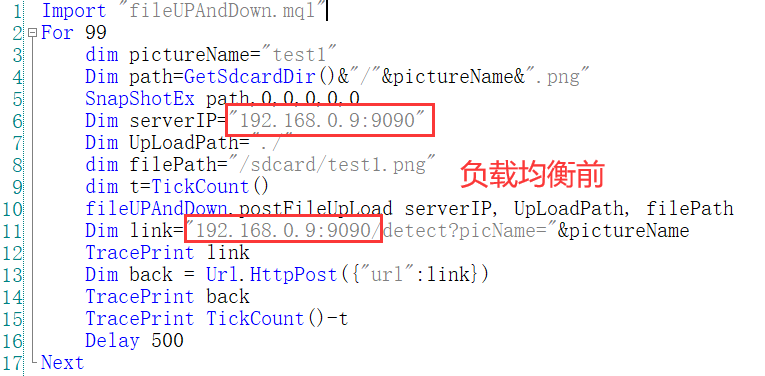
python yoloFlask.py 90925.做了负载均衡后,需要将调用地址端口号更改为Nginx监听端口。比如本地部署调用地址是192.168.0.9:9090/XXX,负载均衡后需要在客户端修改调用地址为192.168.0.9:80/XXX。默认监听80端口。
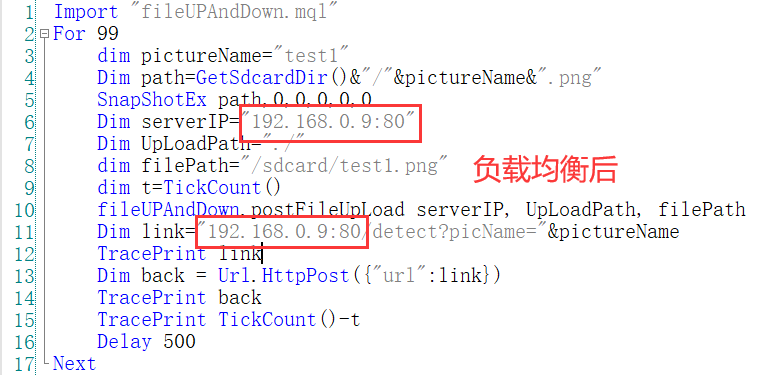
6.验证负载均衡,查看每个Flask实例是否都收到了请求。

